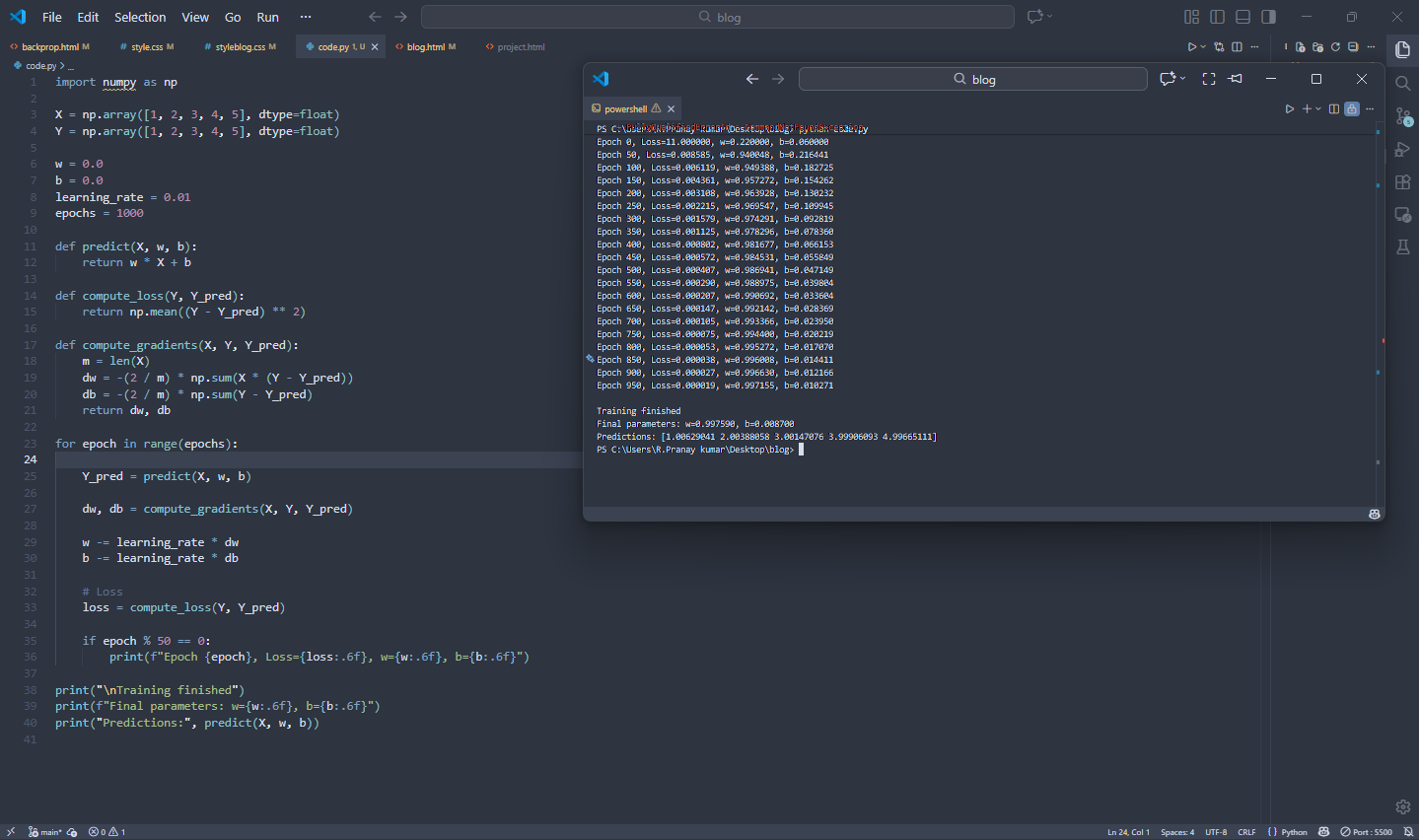
import numpy as np
# Data
X = np.array([1, 2, 3, 4, 5], dtype=float)
Y = np.array([1, 2, 3, 4, 5], dtype=float)
# Parameters
w = 0.0
b = 0.0
learning_rate = 0.01
epochs = 1000
# Forward pass
def predict(X, w, b):
return w * X + b
# Loss
def compute_loss(Y, Y_pred):
return np.mean((Y - Y_pred) ** 2)
# Backpropagation (Batch Gradients)
def compute_gradients(X, Y, Y_pred):
m = len(X)
dw = -(2 / m) * np.sum(X * (Y - Y_pred))
db = -(2 / m) * np.sum(Y - Y_pred)
return dw, db
# Training loop
for epoch in range(epochs):
Y_pred = predict(X, w, b)
dw, db = compute_gradients(X, Y, Y_pred)
w -= learning_rate * dw
b -= learning_rate * db
loss = compute_loss(Y, Y_pred)
if epoch % 50 == 0:
print(f"Epoch {epoch}, Loss={loss:.6f}, w={w:.6f}, b={b:.6f}")
print("\nTraining finished")
print(f"Final parameters: w={w:.6f}, b={b:.6f}")
print("Predictions:", predict(X, w, b))